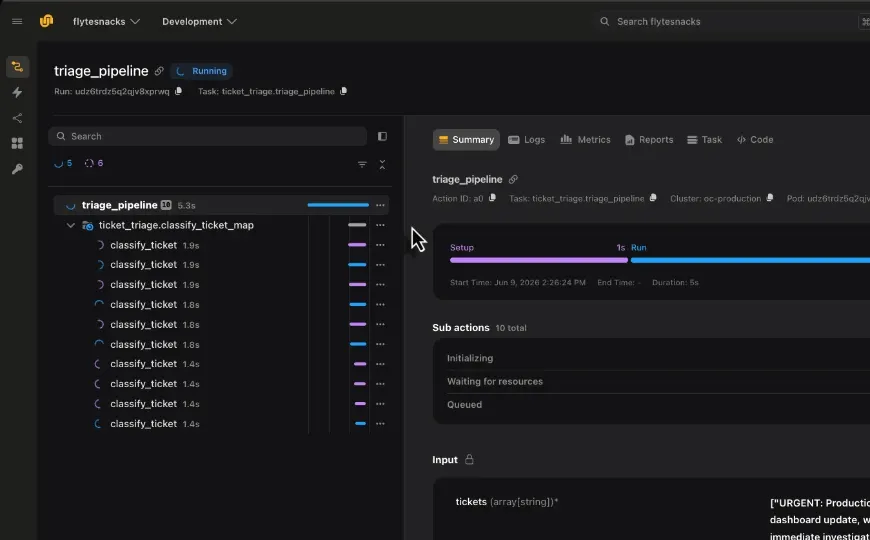
Local development agent harnesses like Claude Code, OpenCode, and Pi make building an agent look easy. You wire up a few tools, point it at a model, ship a demo, and it works beautifully.
But then you try to productionize the same functionality and deploy a long horizon agent that runs on your cloud, in the background, and you ask yourself: "what happens when a tool call OOMs partway through a four-hour batch?", "how do you keep the agent from re-running two hundred dollars of LLM calls after a process crash?", "can it compile and run untrusted code without paying for it on the wrong machine?". This is when a production-grade AI runtime matters.
The problem isn't necessarily the LLM. Agents break in multiple ways:
- Semantic hallucinations (this one is the most well-known)
- Logical bugs (e.g. tool code bugs and malformed tool call payloads)
- Network rate-limits and timeouts (solution: sorry, just try again in a few seconds!)
- Infrastructure failures like OOM (the agent says "I can't provision any more compute")
A lot of engineering focus goes into the first three, but in my experience people rarely think about infrastructure-level concerns, like whether the agent can survive an OOM-kill error on the ninety-ninth out of a hundred steps and pick up where it left off. In this blog, we'll cover how Flyte handles all four sets of concerns and talk about how it's uniquely positioned to handle infrastructure-level agent failures.
What's an AI runtime?
We've been seeing this term pop up in various contexts lately, and our take is that an AI runtime consists of three fundamental pillars:
- Durable orchestration: the substrate that connects data, models, and compute as tasks composed into fault-tolerant workflows.
- Real-time serving: long-running services that serve model endpoints, MCPs, REST-like applications, and human-facing UI applications.
- Multi-silicon infrastructure: the backend that provisions compute that an agent needs to get the right amount of CPUs, memory, GPUs, and XPUs, in whichever cloud it can find.
Different use cases and applications will draw from one, two, or all three of these pillars, and in this blog post we'll see how they apply to building long horizon agents.
Agents on a production-grade AI runtime
Over the last few weeks we've shipped three production-shaped agents using Flyte-native primitives, which are exposed in the flyte.ai.agents package: an `Agent` harness, tools that run on variable compute requirements via Flyte's `@env.tasks`, a durable `MemoryStore`, an on-device sandbox for untrusted code, and task-level retries, traces, and resource overrides:
- The parallelized autoresearch agent: autonomous ML research that proposes TinyGPT configurations, edits `train.py` directly in memory, and fans out parallel training batches on the karpathy/climbmix corpus.
- The AutoSec researcher: autonomous security-ops researcher that scans C source for memory-corruption bugs, hypothesizes a vulnerability, builds a proof-of-concept payload, and validates it by triggering a segmentation fault in a sandbox.
- The drug molecule screening agent: medicinal-chemistry strategist that derives a target profile from a natural-language brief, runs an RDKit virtual screen, reads the funnel, and rescreens once if needed.
These aren't variations on a theme. They're three very different problems that all take on the same shape, because production-grade agents converge on the same sets of concerns.
The pattern, in one block
At a high level, Flyte-native agents share a similar design to many of the agent frameworks out there. The main difference is that the `Agent` itself and the tools they run can each live in different machines with highly variable compute requirements.
Tools are `@env.tasks` decorated with `@tool` and each one runs in its own container with its own resources, retry policy, and caching policy. The agent is configured with a model and an instruction set. Everything beyond that, from the memory, sandbox, OOM recovery, resource sizing, and fan-out, is opt-in. The three agents above pick up different subsets because their workloads are different.
Five things change when you go from demo to production.
1. Untrusted code execution
When an agent produces executable output (Python it wrote to train a model, a C exploit payload it generated, a SQL query against your warehouse), you have figure out where that code runs.
The parallelized autoresearch agent runs in `code_mode` against `claude-sonnet-4-6`. In each iteration it proposes a batch of TinyGPT experiments (depth, width, optimizer, schedule), edits `train.py` to express each one, and asks Flyte to train them. The training corpus is the karpathy/climbmix BPE shard set; the eval metric is validation bits-per-byte (`val_bpb`). Each agent-edited script is staged into a sandbox work directory along with a driver, and executed:
The AutoSec researcher is a more adversarial case. It generates a buffer-overflow payload (`"A" * (buffer_size + 64)`) against vulnerable C source, then compiles and runs the binary inside the same sandbox shape to confirm the crash:
The `-fno-stack-protector` flag is intentional, and the targets under `autosec_research_agent/targets/` are written to be vulnerable, and the validation criterion is whether the binary actually segfaults (indicated by `SIGSEGV`). Therefore, using stack protection would mask the bug we want to confirm. The resulting agent run produces a report that displays the vulnerabilities for each script and the agent’s reasoning behind it:
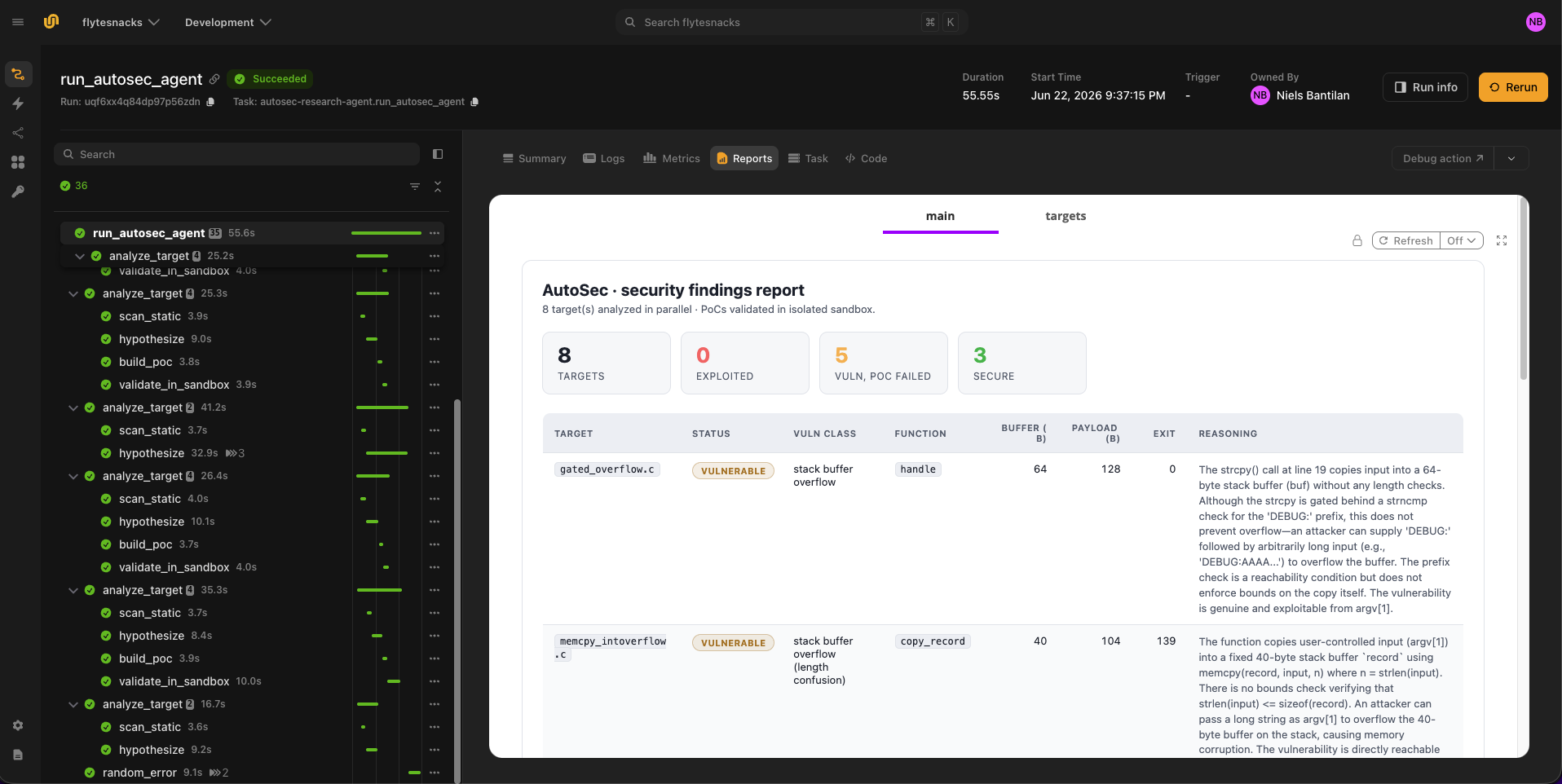
Both agents use `union.sandbox` with the `userns` backend, which opens a Linux user-namespace sandbox on the same node (no VM provisioning), mounts a host work directory, blocks network egress, and tears the session down in `__aexit__`. If the inner process segfaults, hangs, or attempts an outbound connection, the orchestrator records the run and contains the failure inside the sandbox.
Running these in-process is roughly an order of magnitude faster than spinning up a VM, which matters at the rates these agents call the sandbox. The autoresearch agent fans out four experiments per iteration; AutoSec fans out one investigation per target file. Per-call VM provisioning would dominate wall-clock time, and isolation would stop being affordable as a default. For workloads that need stronger isolation than user namespaces or using `bubblewrap` (kernel-level escapes, for instance), you can swap in something like gVisor without changing the call sites.
2. Self-healing through right-sizing
The autoresearch agent runs experiments with very different memory footprints in the same batch. A two-layer TinyGPT with `n_embd=128` fits in a couple of gigabytes; a 24-layer model with `n_embd=1024` and a large device batch size needs closer to sixteen. Picking one resource shape for every experiment wastes compute on the small ones and OOMs the large ones, and the agent is the only thing in the loop that actually knows what each experiment looks like.
The runtime gives the agent a way to size each call individually through a `right_size` `call_handler`:
The handler does two things. First, it asks a small capacity-planning LLM to propose `cpu`/`memory`/`disk` for the specific call. The system prompt makes the model reason in Kubernetes terms about the work implied by the arguments:
The LLM's estimate is treated as a hypothesis, not a contract. The handler clamps it to a fixed range before dispatching:
If the planner asks for 128Gi, the runtime gives it 32Gi. If it asks for 256m, the runtime gives it 2Gi.
Second, if the experiment OOMs anyway, the handler catches the failure and retries with deterministically bumped memory, up to `MAX_OOM_RETRIES`:
OOM detection has to inspect two layers because the training process runs inside the sandbox. If the pod itself dies, Flyte raises `flyte.errors.OOMError`. If only the inner training process dies, the sandbox returns exit code 137 or surfaces an OOM marker in stderr:
The result row carries `oom_retries`, so downstream code (and the agent reading the leaderboard) can distinguish an experiment that landed on its first allocation from one that needed a bump. In a four-experiment batch I ran, `val_bpb` improved from 3.130 to 2.880. Three experiments completed on the first allocation, and the fourth came back from the planner with 8Gi, OOM'd, was retried at 16Gi, and finished. The agent observed a successful experiment with `oom_retries=1`.
The same recovery shape shows up in the AutoSec researcher's static-scan stage, but without the capacity-planning LLM. The tool catches OOM and re-dispatches itself with hardcoded larger resources and a narrower scope:
Two sizing strategies (planner-driven for the autoresearch agent, hardcoded fallback for AutoSec) sharing one underlying primitive: a tool body catches `flyte.errors.OOMError` and re-dispatches the same task via `.override(resources=...)`. The agent doesn't have to model capacity correctly on the first try, and infrastructure failure doesn't propagate out of the tool boundary.
.png)
3. Durable state across runs
A research run that loses its leaderboard when the pod restarts is not a research run. It's four hours of GPU compute you can't reuse.
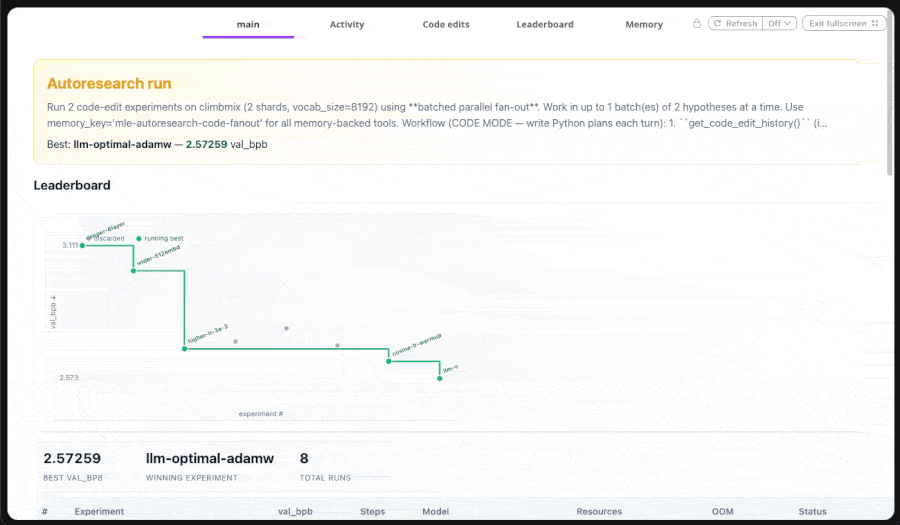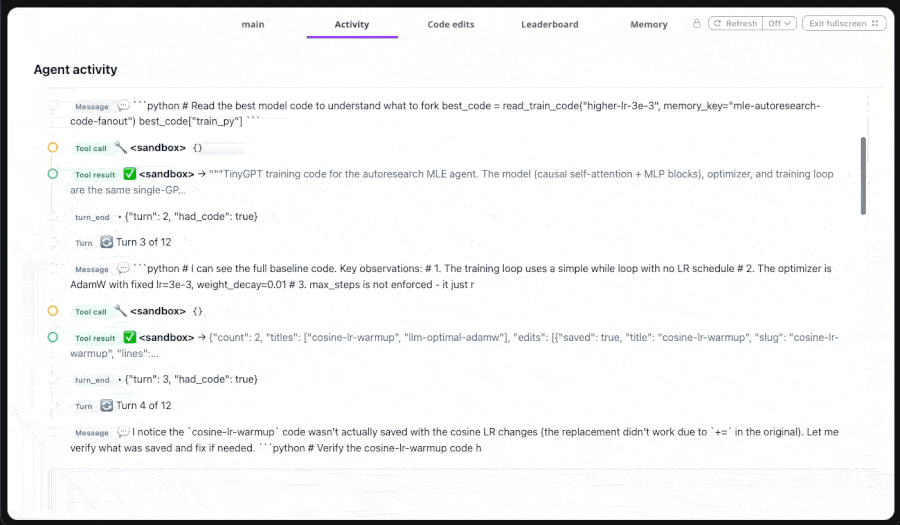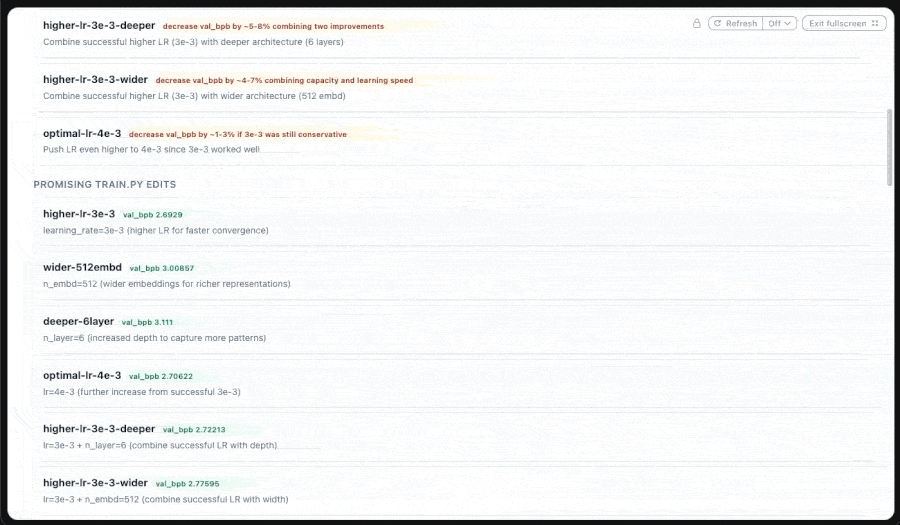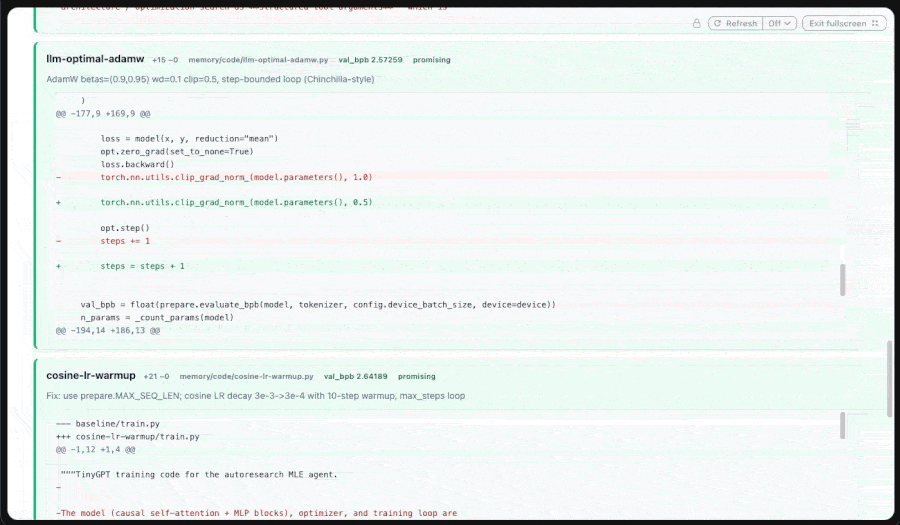
The autoresearch agent persists the leaderboard, the agent-edited `train.py` files (one per experiment at `memory/code/{slug}.py`), the hypotheses recorded before each batch, the per-experiment config overrides, and a config-signature index. All of it lives in `MemoryStore`.
The agent writes to memory through a tool in its own catalog. When it proposes a batch, it calls `edit_train_code_batch` to atomically save every edit:
At the start of every session, the orchestrator hydrates a directive from prior research:
If you re-run with the same `memory_key`, the agent sees its earlier work in the directive. It doesn't redo experiments 1-5 to figure out the best so far; it reads the leaderboard, picks the current frontrunner, and proposes experiment 6. The cost of stopping and restarting is a session boundary, not a redo.
`MemoryStore` is doing something other than what most agent frameworks call memory. It isn't a conversation buffer. Agent-written code lives in it. The leaderboard lives in it. Resuming the agent is closer to handing it back a lab notebook than restoring a chat session.
4. Bounded loops
The most common production failure mode is a loop the agent doesn't escape. The model proposes a change, the metric moves a hair, it proposes another change, and you wake up to a sixty-dollar bill. Each of the three agents enforces some form of bounded reflection in its instructions.
The drug molecule screening agent uses the simplest version, declared in the system prompt:
One rescreen, one relaxed bound, then the agent has to stop. The contract is in the prompt.
The AutoSec researcher layers two bounds. The hypothesis stage is an inner `Agent` with `max_turns=6`, wrapped in an outer Flyte task with `retries=3`:
The inner loop terminates on max turns. The outer terminates on retry budget. Malformed JSON from the inner agent raises in the outer task, which retries, so a bad turn shows up as a clean dict on the next attempt rather than as an unbounded retry storm.
The autoresearch agent's case is the most nuanced because plateaus are a real signal in ML experimentation. Its directive includes a plateau rule that switches strategies after three batches of negligible improvement:
There is also a config-signature index in `MemoryStore` that hashes proposed configurations, so the agent can't accidentally re-run an equivalent experiment under a different title. Three failure-stop conditions exist for free: max turns at the agent level, retry budget at the task level, plateau pivot at the planning level. Each is declared in plain language and enforced by the runtime.
5. Composable, auditable tools
When tools are real Flyte tasks (typed, cached, in their own containers, each carrying its own resources and trace lineage), composition is also an audit-trail decision.
The drug molecule screening agent is the cleanest illustration. Four tools, each `@tool` `@env.task`, each with the durability flag that fits the work:
The library ships with fifteen real drugs: Aspirin, Ibuprofen, Caffeine, Metformin, Paracetamol, Penicillin G, and others. The chemical properties come from RDKit: molecular weight, LogP, hydrogen-bond donors and acceptors, TPSA, QED, Lipinski compliance flags. None of these are LLM outputs. `load_molecules` is cached, so a chemist iterating on the target profile only pays for screening and report generation on each turn. It outputs a `flyte.io.Dir`, which is an object-store-backed directory containing images and other files relating to the molecules in question.
Then, the three downstream tools have `report=True`, so each stage streams an HTML card to the UI as the agent calls it.
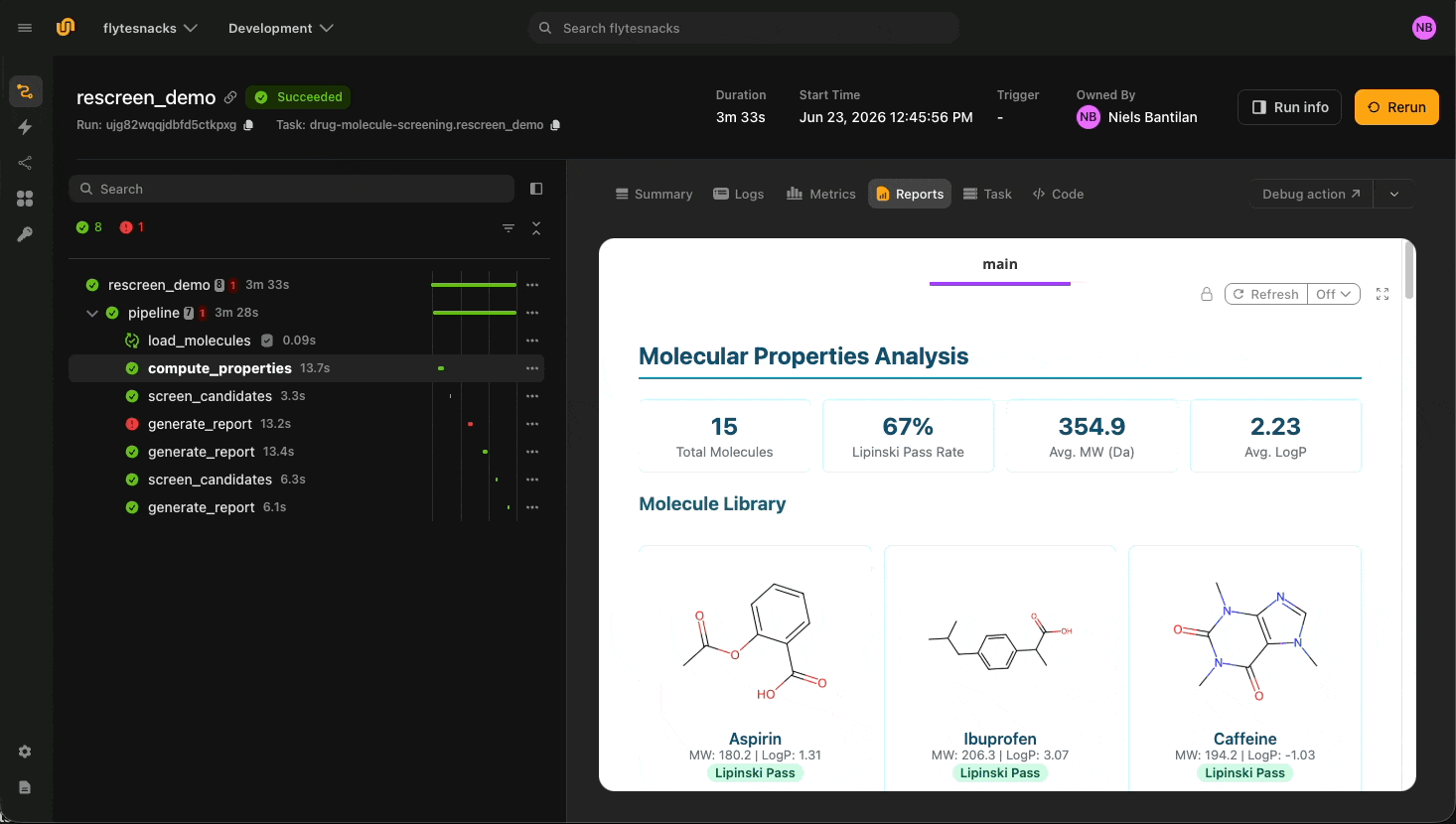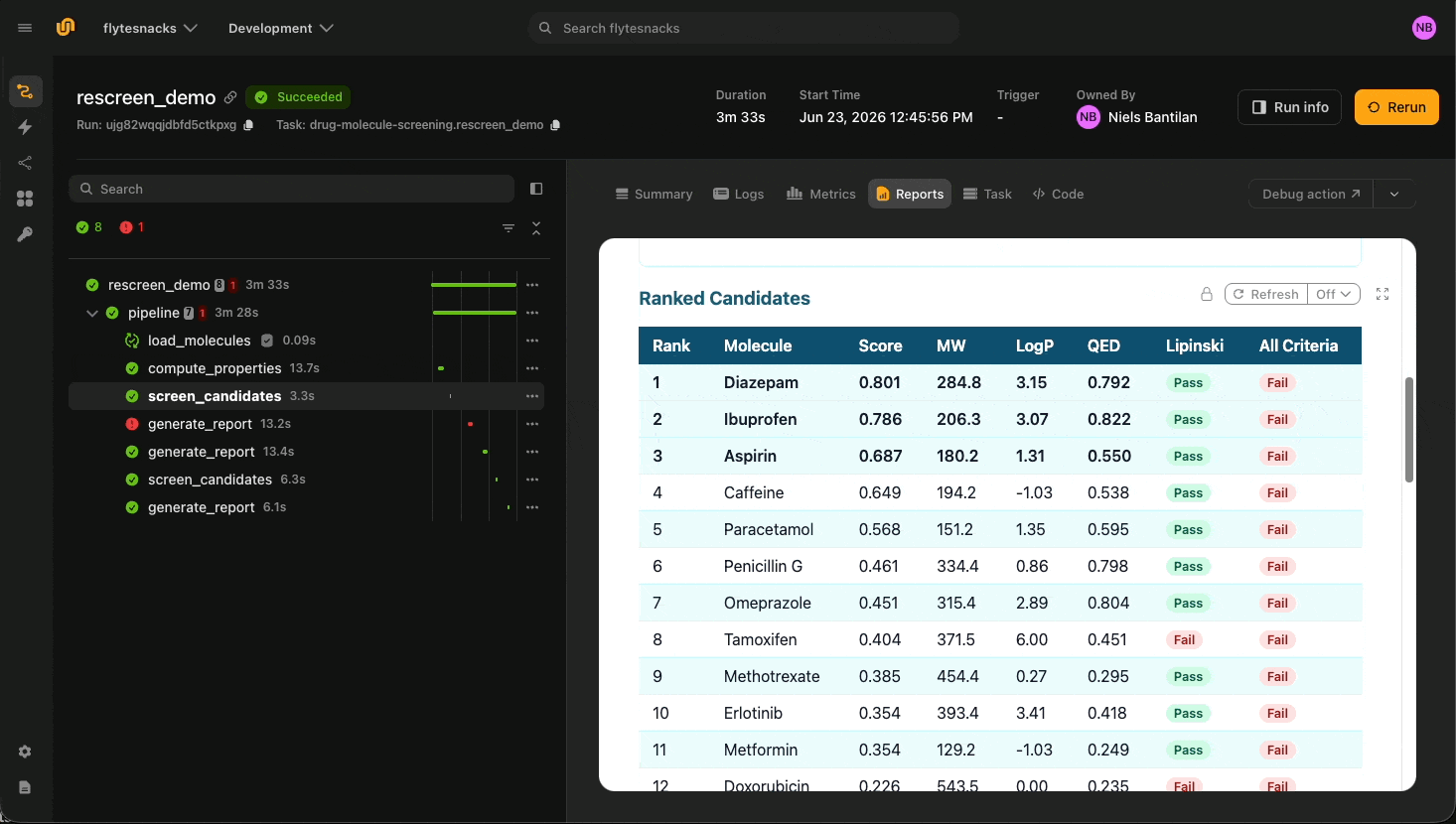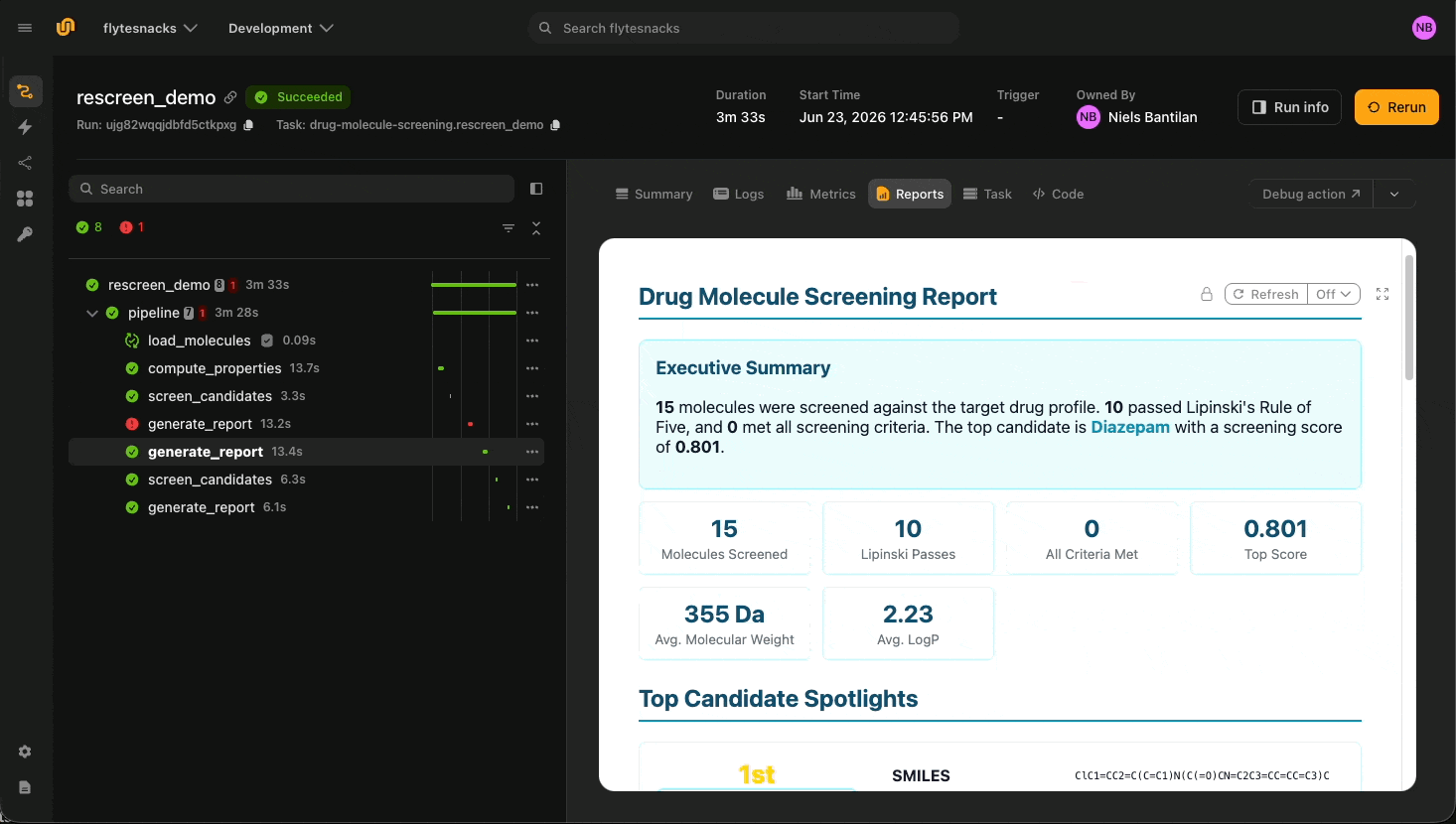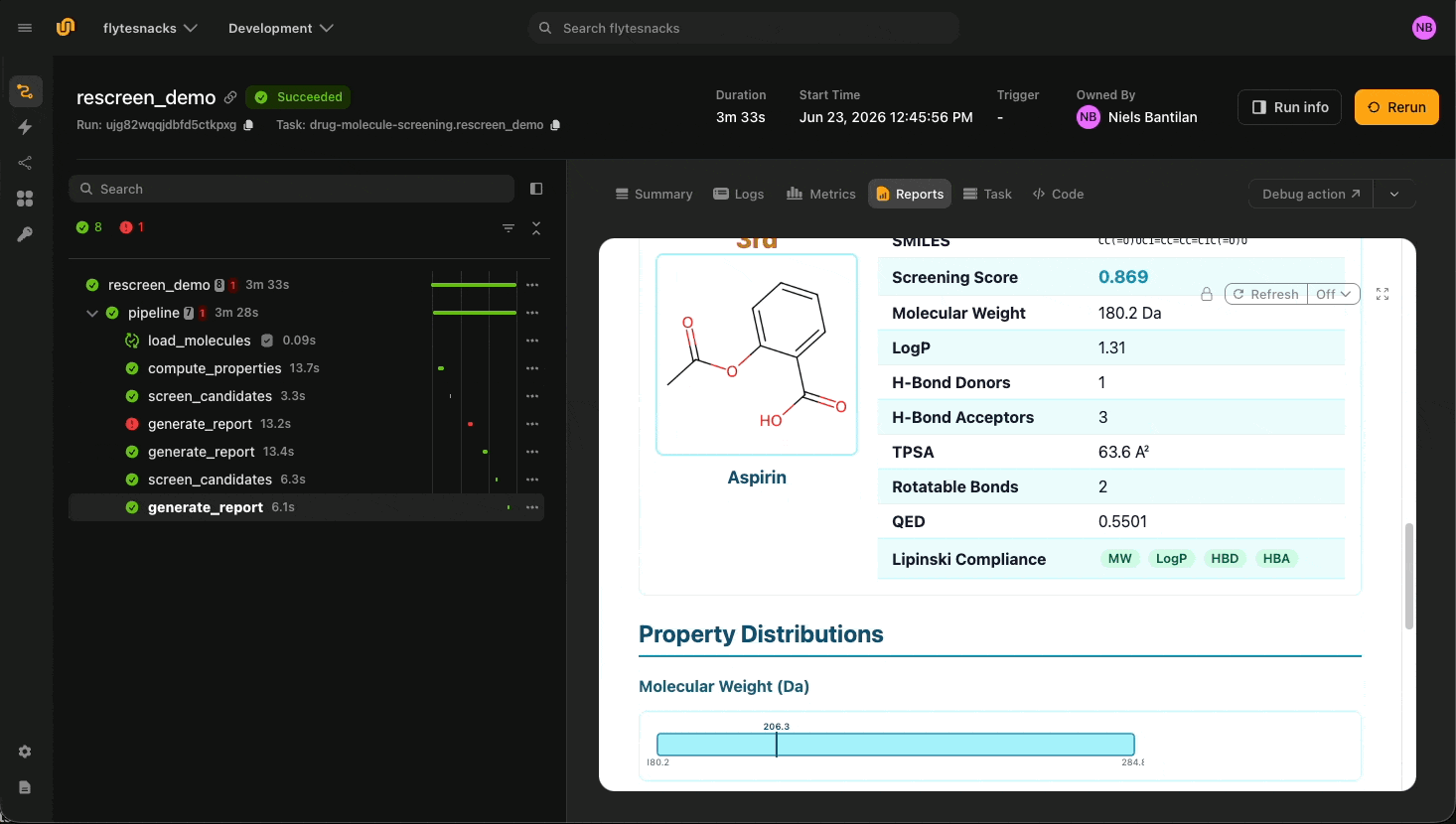
The more interesting property is in the instructions: the agent passes tool outputs verbatim between steps. `screen_candidates` returns a JSON blob; the agent forwards that blob unmodified to `generate_report`. The runtime backs this up with a parser that rejects rewritten input:
If the agent reformats or summarizes the JSON, the next tool refuses it. The runtime trace ends up showing the exact bytes flowing between tools, which is what a chemist or auditor needs to replay a run.
The other agents display the same property. Every LLM call, every sandbox session, every retry, every resource override is a typed step in the run record. The AutoSec orchestrator is small (an `asyncio.gather` over the targets directory), but each per-target investigation is its own Flyte action with independent checkpoints:
Three agents, one runtime
To summarize, we looked at three agents in very different domains:
AI research: the parallelized autoresearch agent runs autonomous ML research over the `karpathy/climbmix corpus`. The agent edits TinyGPT `train.py` in durable memory, fans out experiment batches via flyte.map, sizes each call through an LLM capacity planner with floor/ceiling clamps, runs the experiment in a userns sandbox, and self-heals OOM at two layers (pod and inner process). It exercises most of the runtime: `Agent` + `code_mode=True`, `@tool @env.task`, `MemoryStore`, `flyte.map.aio`, `union.sandbox`, `@tool(call_handler=right_size)` with `task.override(resources=...)`, `@env.task(report=True)`. Tutorial · Code
Security research: The AutoSec researcher finds memory-corruption bugs in C programs and validates them by triggering the crash inside the same userns sandbox shape. It fans out across `targets/*.c` with `asyncio.gather`; the hypothesis stage uses an inner `Agent(max_turns=6)` wrapped in a Flyte task that retries on malformed JSON. The tutorial ships with `AUTOSEC_FORCE_*` env vars (OOM on static scan, 600s LLM timeout, hallucinated tool call) so you can watch the healing happen in the run graph rather than take it on faith. Tutorial · Code
Drug screening: The drug molecule screening agent drives an RDKit virtual screen over fifteen real drugs from a natural-language brief, runs `load_molecules → compute_properties → screen_candidates → generate_report`, and rescreens at most once if the funnel is empty. It is the lightest of the three; it shows that the same `Agent` + `@tool` primitives compose into clean pipelines without sandbox or memory overhead when the workload doesn't need them. Tutorial · Code
Conclusion: make the runtime robust to LLM failures
Most agent frameworks treat the LLM as the durable component and the surrounding infrastructure as glue code. Flyte 2 inverts that. The runtime is the durable layer (tasks, memory, sandbox, retries, traces, reports, resource overrides). The LLM is the flaky component the runtime is built to recover from.
You can implement any of these agents with raw `asyncio` and `httpx`. The control flow isn't difficult. The work is in the long tail: transient API failures, OOMs on a specific config, mid-run crashes that lose leaderboards, untrusted code that has to be isolated and torn down regardless of outcome, agent-proposed resource estimates that need to stay inside a sane envelope. Most teams handle each of these with a different vendor: a scheduler, a secrets manager, an observability tool, a sandbox, a retry wrapper, a capacity-planning service.
With Flyte, you get all of the core primitives you need for building production-grade agents:
In the beginning of this post, we learned that an AI runtime is composed of the three things: durable orchestration, real-time serving, and multi-silicon infrastructure. The agents we talked about here leverage the first and the third, piece. In subsequent posts, we’ll talk more about how you can self-host LLMs (typically small language models or SLMs) on your own infrastructure to perform tasks that don’t require a state-of-the-art LLM to complete.
Lastly, because Flyte provides a pure Python SDK for building agents, you can bring your own agent framework, like LangGraph, Pydantic AI, and more. We’ll also cover more of how you can use Flyte to productionize your existing agent harnesses built in these frameworks and get the same durability guarantees that we showed here today.
Try it
The fastest way to feel the difference is to run any of the three on a Flyte DevBox, a managed Flyte cluster you can stand up in about a minute:
You'll need an Anthropic API key as a Flyte secret. Reports show up in the Union UI. Watch an experiment in the autoresearch agent get sized at 8Gi, OOM, and finish at 16Gi without the agent intervening. Force a hallucinated tool call in the AutoSec researcher with `AUTOSEC_FORCE_BAD_TOOL_CALL=1` and watch the parser raise, the task retry, and the agent finish the investigation. Run the drug molecule screening agent against a strict target profile and watch it rescreen once and stop.
When something goes wrong in any of them, the run record tells you what happened, the agent didn't bill you for the failure, and the next turn keeps moving. That's the part of the agent stack that's worth getting right.