Your coding agent can write Flyte code. The good ones can write correct Flyte code from the docs. None of them can run your tasks, inspect a failed run, retrieve outputs, or grep the actual SDK examples without you copy-pasting output back into the chat. The agent knows how to write; the cluster knows what's actually happening; and the two live in different worlds.
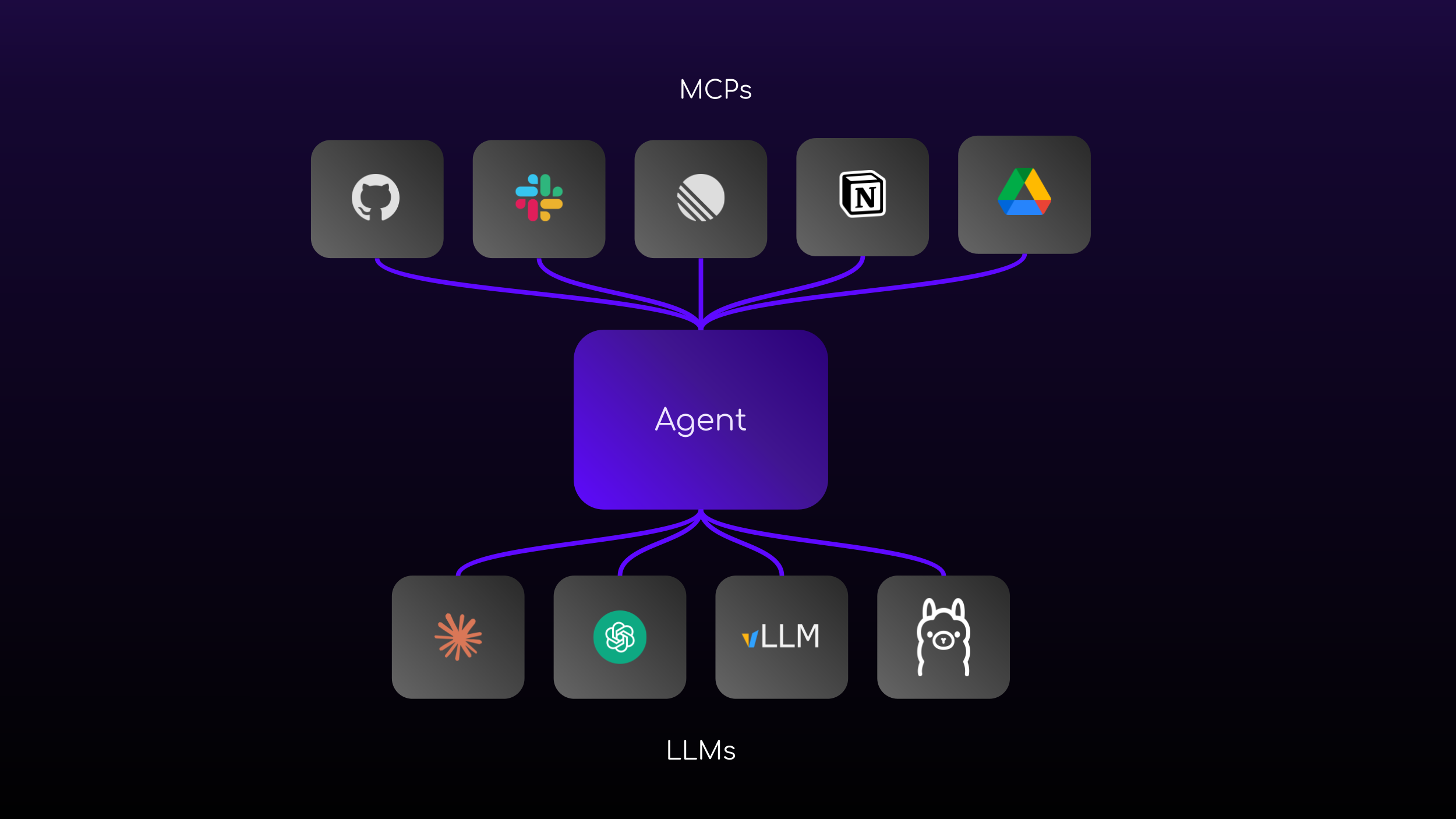
`flyte.ai.mcp.FlyteMCPAppEnvironment` closes that gap. It's an MCP server that exposes your Flyte cluster as a set of standardized tools, so any MCP-aware agent (Claude Code, OpenCode, Cursor) gets direct access to your control plane. List your tasks, run one with arguments, wait for a result, fetch logs from a failed run, search the Flyte SDK examples or the Union docs. The agent decides what to call. The cluster does the work.
The same abstraction, `MCPAppEnvironment`, lets you deploy your own MCP servers for whatever domain your team specializes in: your data warehouse, your release tooling, your internal models. `FlyteMCPAppEnvironment’` is the well-known special case. The general one is a way to ship secure, auth-gated MCP servers as Flyte apps with the same lifecycle and observability you already use for the rest of your code.
In this post we'll walk through what the Flyte MCP server lets your local agent do today, how to scope it for shared and production use, and how to deploy your own MCP server for any domain.
What is MCP, and why does an orchestrator need one?
The Model Context Protocol is a standard for connecting agents to tools. A server exposes a catalog of tools; an agent (or its harness) connects, lists the tools, and calls them. The protocol is transport-agnostic (stdio for local subprocesses, streamable-HTTP for remote servers), and the tool schema is JSON Schema. Claude Code, OpenCode, Cursor, and several other editors are all MCP clients.
For an orchestrator like Flyte, that contract maps cleanly onto two existing concerns:
- Tool surface as control-plane API. A Flyte cluster already has a control-plane API for running tasks, inspecting runs, building images, and reading docs. Exposing that surface through MCP makes the same operations available to any MCP-aware agent without writing a custom client per editor.
- Tool surface as grounding source. Coding agents hallucinate Flyte APIs the same way they hallucinate any Python library. A search-only MCP server that greps actual SDK examples turns "I'll invent some plausible kwargs" into "I'll grep the real example first." The result is grounded, not guessed.
`FlyteMCPAppEnvironment` does both. The same server runs your tasks and grounds the agent in real source code.
What FlyteMCPAppEnvironment ships
`FlyteMCPAppEnvironment` is built on FastMCP and ships a curated set of Flyte tools out of the box, grouped by capability:
The `search` tools are the part most people underrate. The default image already clones the `flyte-sdk` and `unionai-examples` repos and downloads the Union `llms.txt` into `/root`, so search is wired up the moment the server starts. The agent doesn't have to guess at the API. It greps a real example and uses that.
The simplest deployment is one block of Python:
`flyte.serve` deploys the server as a long-running Flyte app. The endpoint is stable, and any MCP client can connect.
Two ways to run it
There are two modes that map to how you actually develop. For solo work on your laptop, the `flyte[mcp]` extra ships a `flyte-mcp` CLI you can run with `uvx`, no install required:
`uvx` downloads `flyte[mcp]` into an isolated environment, runs the server, and the MCP client (Claude Code, OpenCode) manages the subprocess. The server reads your active Flyte config, so whichever cluster you're pointed at is what your agent operates on.
For shared or production use, deploy `FlyteMCPAppEnvironment` as an app and connect over HTTP. Same tools, stable endpoint, auth-gated:
This is the difference between "Claude Code can run Flyte tasks on my laptop's cluster" and "Claude Code can run Flyte tasks on our shared staging cluster, with my auth, and the audit trail lives in the cluster's run record."
The development loop you actually want
Local development with the `flyte` CLI and remote debugging via MCP become the same loop:
- Your agent writes a task in your local file. You and the agent lint and test it locally with `flyte run --local --tui`.
- When local execution is the wrong fidelity (you need GPU, you need a real S3 bucket, you need to reproduce a remote-only bug), the agent calls `build_uv_script_image_remote` and `run_uv_script_remote` to ship it to the cluster.
- When it fails, the agent calls `get_run` and `get_run_io` and reads the actual failure. No copy-paste, no screenshots.
- When it needs to know how the SDK does something, it calls `search_flyte_sdk_examples` and reads the real example instead of inventing an API that doesn't exist.
That last point is the grounding loop. `search_full_docs` and the two example-search tools ground the agent in the actual current SDK. The agent's "what does `flyte.TaskEnvironment` accept?" question gets answered by reading the real code, not by guessing from training data.
Scoping the server for shared use
A server with every tool enabled is fine for trusted local use. For anything shared, you want to narrow it. There are three layers.
Tool groups are the coarsest filter. Enable only what's needed:
Individual tools are tighter, for a strictly read-only server:
Allowlists are the tightest. They restrict which resources a tool can touch, so you can safely expose `run_task` to an agent without giving it the keys to the cluster:
Anything outside the allowlist is rejected. Compose those three layers and you can ship an MCP server that lets an agent monitor production runs and trigger one specific retrain, and nothing else.
Try it: the public Flyte MCP server
We host a public Flyte MCP server with only the docs and example search tools enabled, so you can plug it into your local agent and feel the grounding loop without setting up auth: https://flyte-mcp.apps.demo.hosted.unionai.cloud/
Add it to Claude Code as a remote HTTP MCP server:
Now ask Claude Code "how do I attach a `flyte.Cron` trigger to a task?" and watch it call `search_flyte_sdk_examples` and `search_full_docs` before answering. The answer comes back with the right import, the right argument names, and a real example to crib from.
This server has no `task`, `run`, or `app` tools, so it can't touch a cluster. It's the grounding half of the loop, hosted for the community.
Beyond Flyte: MCPAppEnvironment for your domain
`FlyteMCPAppEnvironment` is just a specialized subclass of `MCPAppEnvironment`. The general primitive lets you turn any FastMCP server into a deployed Flyte app:
That's it. Your data team has an MCP server that knows about your warehouse, your customer model, your billing system, exposed through tools the agent uses the same way it uses `search_flyte_sdk_examples`. The server runs as a Flyte app with the auth, observability, and lifecycle handling you already get from the Flyte control plane.
A real example of this composition is the release-shepherd agent in the `flyte-sdk` examples. It deploys two stub MCP servers (Slack and GitHub) and a Flyte-task tool, then connects an `Agent` to all three. From the LLM's perspective they're indistinguishable, just tools in the catalog. Note the `tool_filter` argument: you narrow the surface the LLM sees, not the whole server.
Swap the stubs for real Slack and GitHub MCP servers and this is the production pattern: deployed, scoped, auth-gated MCP servers your agents compose with native Flyte tasks.
Deploy your own MCP server
The fastest path to running one of these (Flyte MCP, a custom MCP, or both side-by-side) is a Flyte DevBox, a managed Flyte cluster you can stand up in a minute. Deploy any of the examples in `flyte-sdk/examples/mcp` and connect Claude Code to the resulting endpoint. The whole loop (write task, run remotely, debug remotely, search docs) is local in feel but cluster-backed in capability.
Enterprise: your own FlyteMCPAppEnvironment, with secure control-plane access
The public MCP server is search-only on purpose. If you want a Flyte MCP server connected to your production control plane (running your tasks, reading your run metadata, gated by your auth), you don't host it on the internet. You deploy it inside your Union cluster, with your secrets and your allowlists.
That's the production path: a `FlyteMCPAppEnvironment` deployed against your control plane, with `task_allowlist` and `app_allowlist` scoped to what your agents are authorized to drive, and HTTP auth fronted by your identity provider. The same agent setup that grounds against the public docs becomes the agent setup that runs your nightly retraining and reads your prod run logs. If that's the use case you're staring at, talk to us. The serving primitives are open source; the secure deployment against your cluster is what we help with.
Conclusion: MCP servers are first-class Flyte apps
To summarize, MCP closes the gap between your coding agent and the systems it actually needs to operate. With Flyte, those servers are first-class deployable surfaces, not glue code:
Local grounding: `uvx --from "flyte[mcp]" flyte-mcp` gives Claude Code or OpenCode the search tools to ground itself in real Flyte examples without inventing kwargs. Plug into the public server for docs and example search only.
Shared cluster operation: `FlyteMCPAppEnvironment` deployed as a Flyte app gives a team an HTTP MCP endpoint, scoped with `tool_groups`, `tools`, or per-resource allowlists. Auth-gated, observable, and audit-tracked through the same control plane the team already uses.
Custom domain MCPs: `MCPAppEnvironment` wraps any FastMCP server (warehouse, release tooling, internal models) into a deployed Flyte app. Same auth, observability, and lifecycle. The release-shepherd example shows how an `Agent` composes Flyte-task tools and remote MCP tools in one catalog.
Enterprise: a `FlyteMCPAppEnvironment` connected to your production control plane, inside your BYOC perimeter, with your allowlists and your identity provider. The serving primitives are open source. The secure deployment is what we help with.
The thread connecting all four is that MCP isn't a separate stack. It's a server type Flyte already knows how to deploy, scope, and observe. The Flyte tools are one useful, opinionated example. Yours can be the next.
Try it
Three concrete starting points, in increasing order of commitment:
The source for `flyte.ai.mcp` and the example servers is in `flyte-sdk/src/flyte/ai/mcp` and `flyte-sdk/examples/mcp`. The release-shepherd agent that composes MCP servers with Flyte-task tools is in `examples/agents/flyte_agent`.